- PacketFabric流
- PacketFabric’s WAY
- PacketFabric流とは、PacketFabricのスタッフ・エンジニアによる
ネットワーク・ソリューション等に関する情報配信メディアです。 
Kubernetes Cluster High Availability構成 前編「周辺システム構築」
2021年03月16日
事業開発担当マネージャー兼
ネットワークオペレーションセンター長
間庭 一宏
今回のINAP流ブログでは、Kubernetes clusterをhigh availability構成(以下HA)で組み上げて無事走らせるに至るまでをご紹介する。前編はKubernetes clusterの周辺システムの構築で、後編でKubernetes clusterの構築を説明する。
現在のINAPのサービスメニューに載っておらず、かといって業務とは全く無関係とまではいかず、つまり仕事中に書いていても遊んでいるわけではないと主張でき、敢えて敷居の高そうな分野ということでこのコンテナー仮想化を選んだ。しかし、いざ検証を始めると苦心惨憺たるものがあった。Kubernetesを生業としているサービス事業者にとってはこんなことは朝飯前なのであろうが、私自身にとっては大いに得るところがあった。こんな私の猥文も、インターネットの一隅に置いておけば、誰かしらの参考になるかもしれない。そんな淡い期待から、頼まれもせぬのに鼻息荒く筆を執った次第である。決して遊んでいるわけではない。

検証にあたり、以下の二冊の書籍を読み込んだ。いずれも洋書であるが、O’Reillyの方は誤植がひどく、おおいに閉口した。
Kubernetes Up and Running – O’Reilly
Mastering Kubernetes Third Edition – Packt Publishing
今回の執筆にあたり、本家https://kubernetes.io/docs/以外にも、以下のサイトを大いに参考にさせていただいた。
https://github.com/kubernetes/kubeadm/blob/master/docs/ha-considerations.md
https://kifarunix.com/configure-highly-available-haproxy-with-keepalived-on-ubuntu-20-04/
https://kifarunix.com/install-and-setup-haproxy-on-ubuntu-20-04/
検証の目的
まず3台のKubernetes control-plane nodeでHAを構成し、up and runningさせる。そして1台のcontrol plane nodeを停止してもサービスが続行することを検証する。あくまでHAの検証を主目的とする。よって、podのscale outやrolling updateなどは対象外とした。
構成図
検証した構成は下記の通りである。
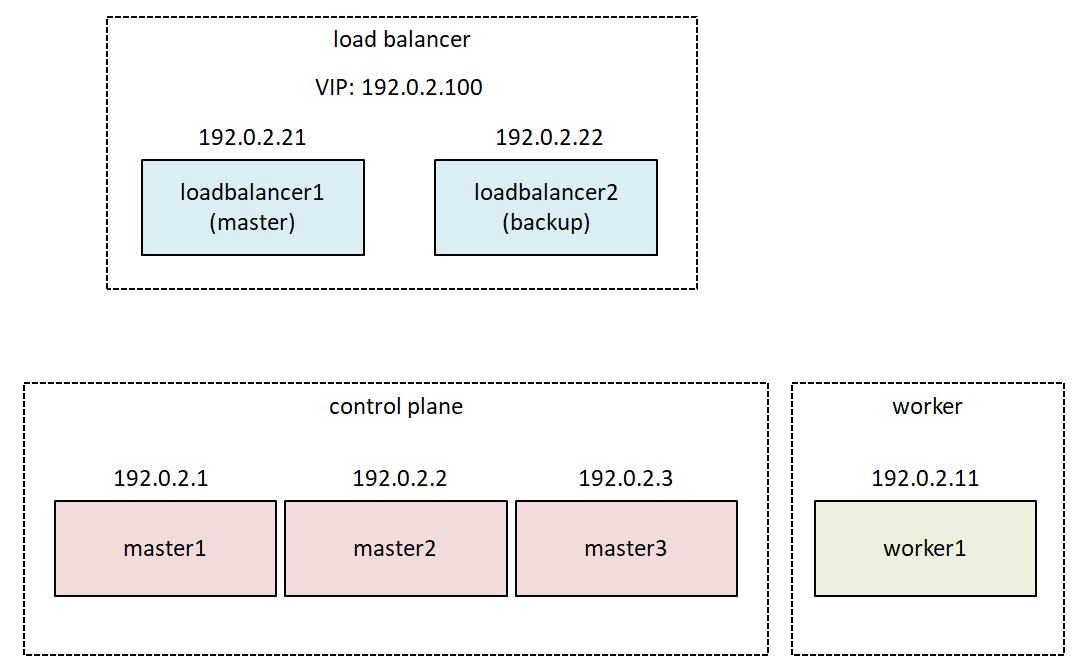
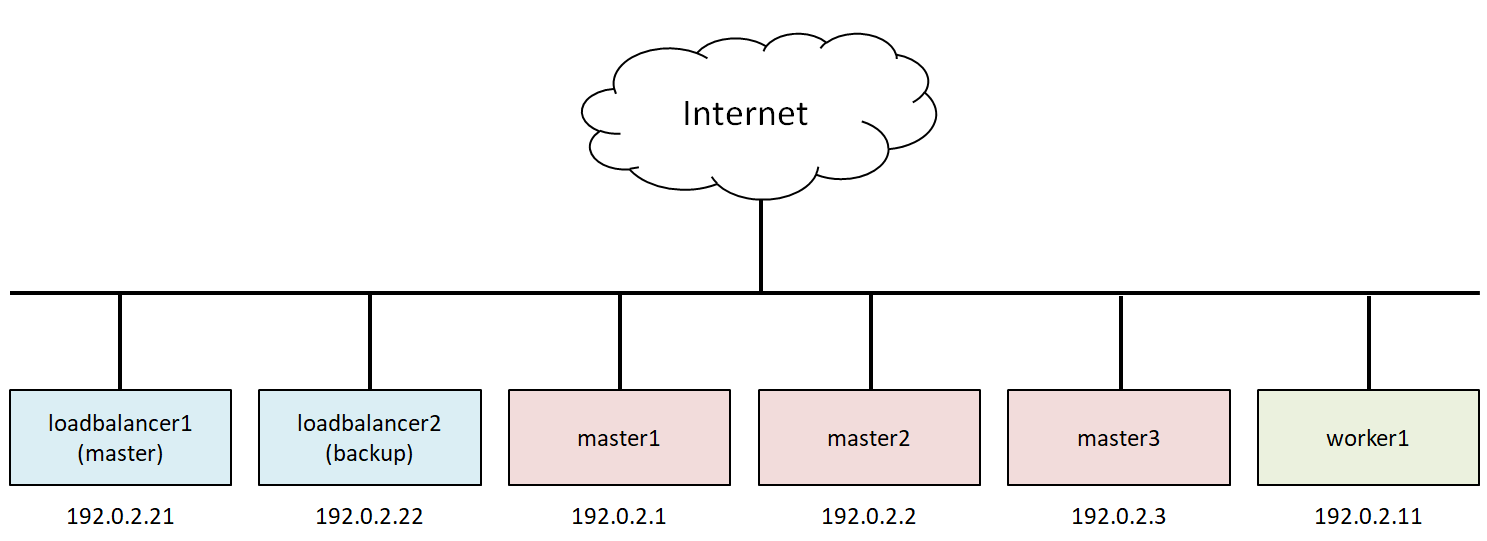
Stacked etcd topology で展開せられている世界を、米国親会社のINAP Cloudで構築した。これはOpenStackベースである。仮想ネットワーク(VLAN)の構成も、最もシンプルなフラットネットワークとした。ただでさえ難解なkubernetesの、control planeのHAの検証に専念するためである。あれもこれもとてんこ盛りにして、気付いたら何の検証をしているのか分からない…という事態は避けたい。尚、IPアドレスは親会社のグローバルIPがfloating IPとして割り当てられるが、文書用の予約IPアドレスに書き換えていることをお断りしておく。
control-plane nodeは奇数台である必要がある。これはcontrol planeのコンポーネントであるetcdデータベースがRaftを採用しているためである。3台のHAであれば、うち1台の障害停止を許容でき、5台であれば2台までの停止を許容できる…といった具合である。
Worker nodeは1台で良い。これも先ほど言及したように、Control planeのHAの検証がメインであるからである。Worker nodeは1台でも2台でも今回の検証内容は変わらない。
補足事項
説明の簡素化のために、直接rootユーザーでログインして構築を進めた。apt updateやapt install、systemctlといった頻出コマンドとその出力結果の類は、極力省略した。枝葉末節の説明を省いて検証の主目的に集中するためである。
しかしKubernetes HA clusterに直接関係はないが、その動作に深く関わるロードバランサーやfirewalldといった周辺情報には多くのページを割くことになった。
「…」は省略を意味している。
インスタンスの作成
OSは全てUbuntuの、執筆当時最新の20.04とした。
Control-Plane Node
主役となるcontrol-plane nodeである。スペックはこれくらいあれば充分であろう。同flavorで3台のインスタンスを立ち上げる。
いくつか仮想VLANが私のお遊び用アカウントに割り当てられているが、今回はシンプルなフラットネットワークなのでインターネットに面したこのWAN2243だけを選択する。他の全インスタンスも同様である。
Worker Node
Worker nodeはもう少し色を付けてみた。16 vCPU/64GBメモリーもあれば充分であろう。
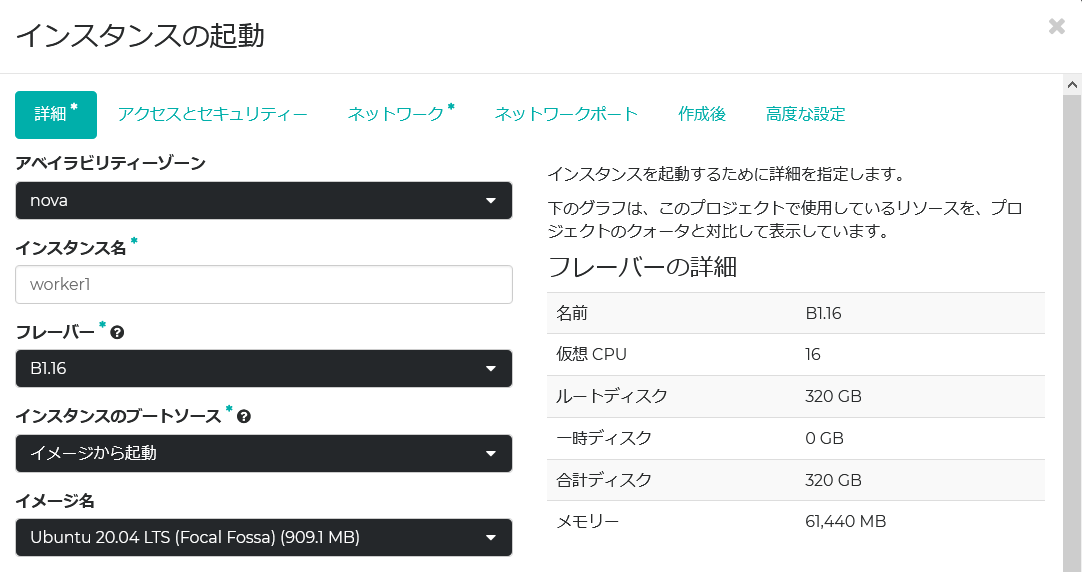
ロードバランサ―
…あまり派手にリソースを喰い荒らすと、米国本社のクラウド監視部隊に見つかって怒られる恐れがある。実を言うと、このブログ執筆中にも彼らに「ちょっと助けてもらえるかしら。技術ブログ書いているだけだからurgentじゃないので」と言葉巧みにチケットをオープンさせて、実は大いに難題を持ちかけた結果、Tier 3クラウドエンジニアにまでエスカレーションされてしまった。何かと私は目を付けられているので、ロードバランサ―は吝嗇感が漂うが、これくらいのスペックにしておこう。
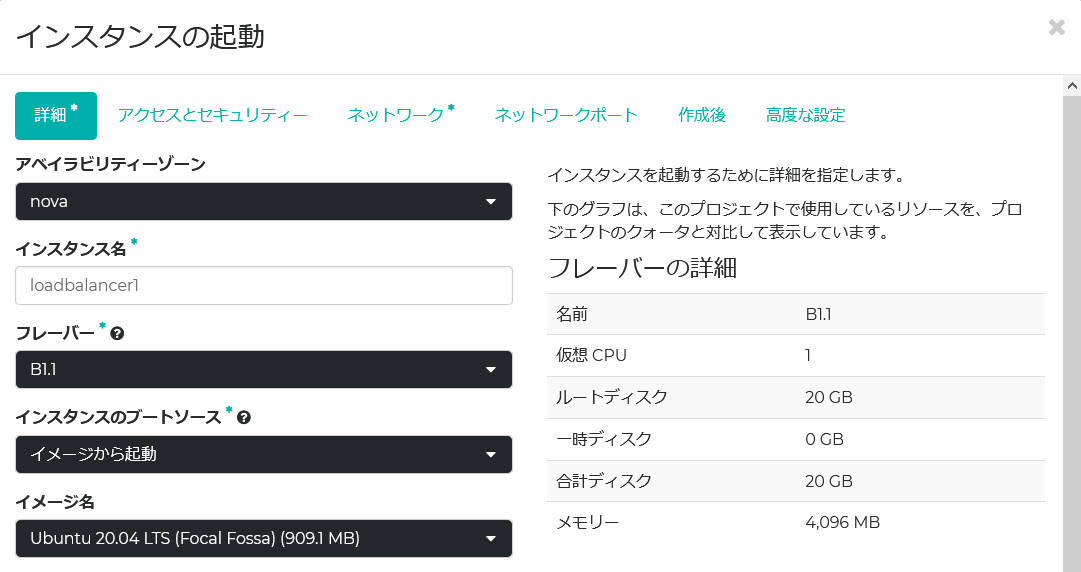
Failover IP
今回ロードバランサーの仮想IPを192.0.2.100/24としたが、OpenStackのfloating IPはインスタンスに対して割り当てられる。然るに仮想IPは、障害時にインスタンス間を移動する。つまりインスタンスに対して1対1で割り当てることができない。この場合、インスタンス間を移動するfailover IPを外部からアクセス可能にするには、OpenStack上でallowed addressを設定する。これはHorizon Dashboardから設定できる。
Allowed addressを設定する対象は、ポートである。ロードバランサーに割り当てられたIPアドレス(ポート)をちくちくとクリックしていくと、該当の設定画面にたどり着く。ロードバランサーは2台構成なので、それぞれのIPアドレス(ポート)のallowed addressに、仮想IP: 192.0.2.100/24を設定する。ところでこの仮想IPは、実際は該当セグメントの未使用グローバルIPアドレスである。
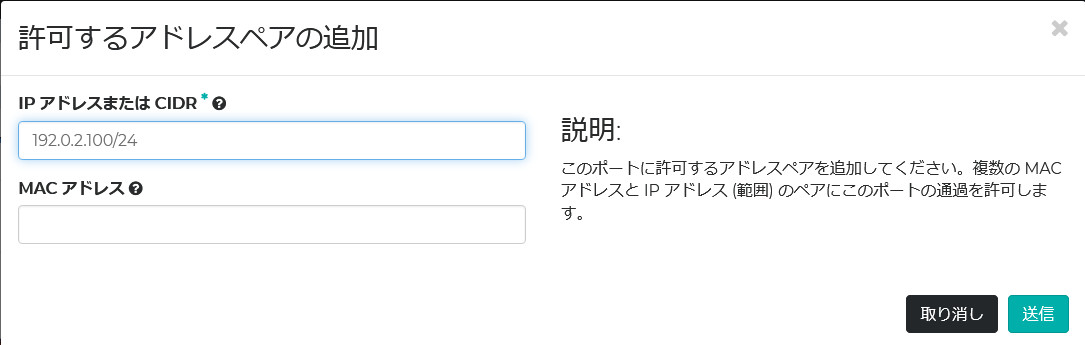
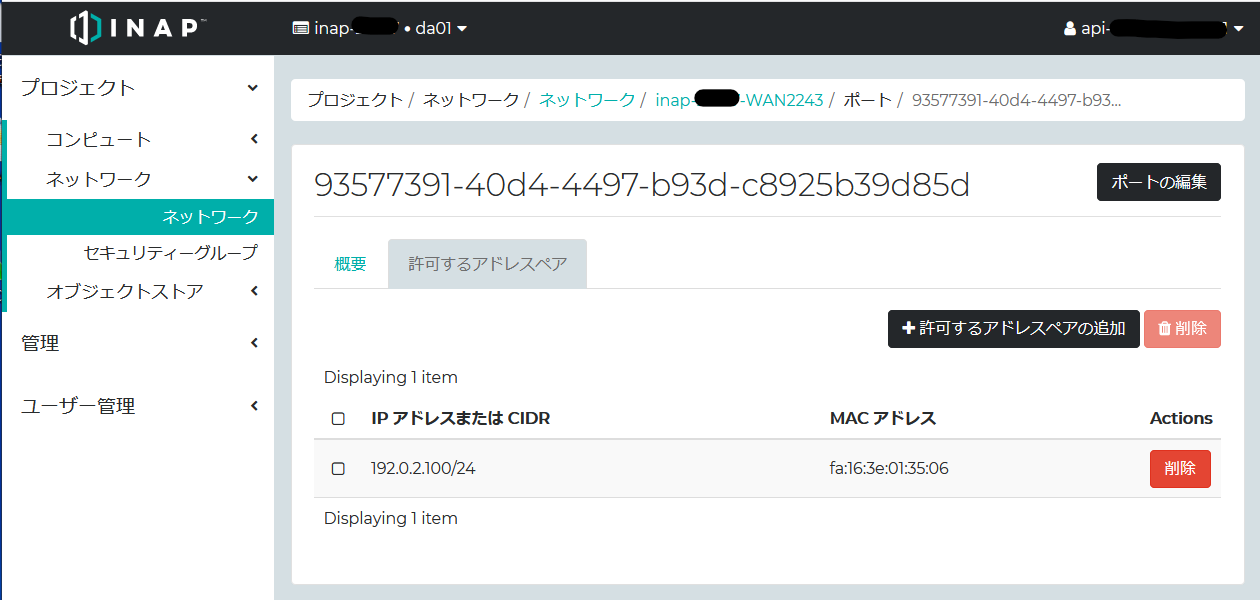
以上でOpenStackでの作業は完了である。以降、各インスタンスにSSHログインして構築を進める。
ロードバランサーの構築
ロードバランサーとなるnodeには、KeepalivedとHAProxyをインストールする。ファイアウォールはfirewalldを別途インストールした。私は不勉強にして未だにUbuntu標準のファイアウォールUFWの扱いを知らないためである。Keepalived.conf以外は2台のロードバランサーで同一設定を施す。
Firewalld
Firewalldをインストールし、OS起動時に自動起動するよう設定する。
# ufw disable
# apt install firewalld
# systemctl enable firewalld
# systemctl start firewalld
# firewall-cmd --state
running
Firewalldのバージョンは、0.8.2であった。
# firewall-cmd --version
0.8.2
KeepalivedのVRRP通信を許可する。これを許可しないと2台のロードバランサーがお互いの状態を確認できず、結果として両者がアクティブになってしまう。firewalldでVRRPは事前定義されていないため、–add-rich-ruleで設定した。VRRPのマルチキャストアドレスは224.0.0.18、プロトコル番号は112である。
RFC 3768(VRRP)の抜粋
5.2.2. Destination Address
The IP multicast address as assigned by the IANA for VRRP is:
224.0.0.18
5.2.4. Protocol
The IP protocol number assigned by the IANA for VRRP is 112
(decimal).
設定コマンドは以下の通りである。Zoneはデフォルトのpublicを使った。この他にiptablesのルールに直接JUMPさせる方法もあるらしい。
# firewall-cmd \
--zone=public --permanent \
--add-rich-rule='rule family="ipv4" destination address="224.0.0.18" protocol value="112" accept'
# firewall-cmd --reload
# firewall-cmd --zone=public --list-rich-rules rule family="ipv4" destination address="224.0.0.18" protocol value="112" acceptKubernetes API serverのポート6443を許可する。
# firewall-cmd --zone=public --add-port=6443/tcp --permanent
# firewall-cmd --reload
# firewall-cmd --zone=public --list-ports 6443/tcp
Keepalived
パッケージをインストールする。本ブログ執筆時のバージョンは2.0.19である。
# apt install keepalived
# keepalived --version
Keepalived v2.0.19 (10/19,2019)
Keepalived (とHAProxy)で負荷分散するには、仮想IP(failover IP)が必要である。この仮想IPは直接仮想NICに割り当てられるのではなく、Keepalivedがnon localに割り当てるのであり、このnon localな仮想IPを使うことをカーネルパラメーターで指示する必要がある。
# echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.d/99-sysctl.conf
# shutdown -r now
# sysctl net.ipv4.ip_nonlocal_bind
net.ipv4.ip_nonlocal_bind = 1
keepalived.conf
設定ファイルkeepalived.confを作成する。
/etc/keepalived/keepalived.conf(MASTER側)
global_defs {
router_id INAP_LVS
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens3
virtual_router_id 51
priority 101
authentication {
auth_type PASS
auth_pass P@ssw0rd
}
virtual_ipaddress {
192.0.2.100/24
}
track_script {
check_haproxy
}
}
/etc/keepalived/keepalived.conf(BACKUP側)
MASTER側との相違点を赤字で示した。
global_defs {
router_id INAP_LVS
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens3
virtual_router_id 51
priority 100
authentication {
auth_type PASS
auth_pass P@ssw0rd
}
virtual_ipaddress {
192.0.2.100/24
}
track_script {
check_haproxy
}
}
以下に特記すべき部分を説明する。
vrrp_script {} ブロック
何を以って障害と判断しbackup側のKeepalivedにフェールオーバーさせるか。script “/etc/keepalived/check_haproxy.sh”とあるように、HAProxyの機能、つまり負荷分散機能が死んでいると判断した時が即ちフェールオーバーすべき時である。そしてその監視スクリプトは以下の通りである。
/etc/keepalived/check_haproxy.sh
#!/bin/sh
VIP=192.0.2.100
if ! nc -z -w 3 localhost 6443
then
echo "Port 6443 is not available." 1>&2
exit 1
fi
if ip address show secondary | grep -q $VIP
then
if ! curl --silent --max-time 2 --insecure https://$VIP:6443/ -o /dev/null
then
echo "https://$VIP:6443/ is not available." 1>&2
exit 1
fi
fi
まず待ち受けポート=6443が空いていない事には負荷分散も何もない。これを確認するには、ncコマンドをポートスキャンモード(-z)で実行すれば事は足りる。ポートは空いているがじいっと待たれていても困るので、3秒でさっさと諦めてもらう(-w 3)。ncコマンドが失敗したら、短く悲痛な叫びをあげて(Port 6443 is not available.)、exit 1してもらう。これをトリガーにKeepalived君はフェールオーバーを開始する。
...
if ! nc -z -w 3 localhost 6443
then
echo "Port 6443 is not available." 1>&2
exit 1
fi
...
ところで”Port 6443 is not available.”をエラー出力にリダイレクトしてもjournalctlのログに出てこない。悲痛な叫びはどこに捨てられてしまっているのであろう。まあHAの検証には関係ないので後日の課題とする。
journalctlの出力
Feb 28 08:49:38 loadbalancer1 Keepalived_vrrp[40333]: Script `check_haproxy` now returning 1
ポート6443が空いていたら、今度は肝心の負荷分散機能のチェックに進む。Keepalivedが現在MASTERであれば、仮想IPとポート6443に対してcurlすることで、3台のKubernetes api-serverの内1台にリダイレクトされる。これにより何らかの応答があれば良し。応答がなければ負荷分散機能が死んでいるので、やはりフェールオーバーを発動すべきなのである。
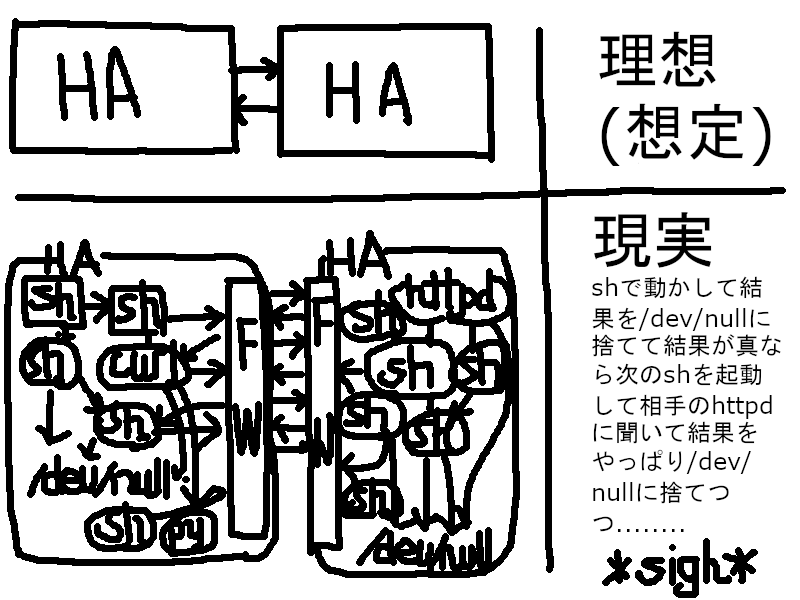
ところでKeepalivedが現在MASTERなのかBACKUPなのか、いかように知り得るか。これが、コマンド一つで出てこないのである。Keepalivedの機能としては、notifyスクリプトがある。keepalived.confのvrrp_instance{}ブロックの中でnotifyスクリプトを実行させると、3番目のパラメーターでMASTER/BACKUPが返される。しかし、これは状態が遷移した時に初めてMASTER/BACKUPが返されるので、Keepalivedの起動後から最初のフェールオーバーまでは状態が分からない。よって割り当てられたIPアドレスの中にセカンダリIPアドレスとして仮想IPが割り当てられているかを確認することでMASTER/BACKUPを判断することとした。
...
if ip address show secondary | grep -q $VIP
then
if ! curl --silent --max-time 2 --insecure https://$VIP:6443/ -o /dev/null
then
echo "https://$VIP:6443/ is not available." 1>&2
exit 1
fi
fi
...
自身がMASTERであれば、Kubernetes API-Serverにcurlを実行し、その戻りがなければexit 1してフェールオーバーする。ちなみにhttps://192.0.2.100:6443/の戻りは以下の通りForbidden 403である。戻りは何でもよく、要はHTTPSの応答があればよい。
# curl --insecure https://192.0.2.100:6443/
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "forbidden: User \"system:anonymous\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {
},
"code": 403
check_haproxy.shを3秒おきに実行し、返り値が1であれば、自信の重みを2つ下げて(priority 101 – 2 = 99)、相手側がBACKUPからMASTERとなる(priority 100)。
vrrp_instance {} ブロック
ここで特記すべきはpriorityと仮想IPの指定箇所くらいであろう。
...
virtual_ipaddress {
192.0.2.100/24
}
...
前述のcheck_haproxyスクリプトもここで指定する。
...
track_script {
check_haproxy
}
...
2台のkeepalived.confが完成したら、keepalivedサービスを起動する。
# systemctl enable Keepalived
# systemctl start Keepalived
# systemctl status Keepalived
Kubernetes api-serverが未構築なのでcheck_haproxyスクリプトが失敗しているが無視してよい。keepalivedサービスがkeepalived.confを読み込み、サービス起動に成功していることを確認する。
HAProxy
執筆時のUbuntu 20.04のHAProxyパッケージは2.0.x系だが、Vincent Bernat が管理しているリポジトリ―を使わせていただくと2.3.x系が入手できる。
# apt install software-properties-common
# add-apt-repository ppa:vbernat/haproxy-2.3
# apt update
# apt install haproxy
# haproxy -v
HA-Proxy version 2.3.5-1ppa1~focal 2021/02/06 - https://haproxy.org/
Status: stable branch - will stop receiving fixes around Q1 2022.
haproxy.cfg
設定ファイル/etc/haproxy/haproxy.cfgを作成する。2台とも同一の設定である。
global
log /dev/log local0
log /dev/log local1 notice
user haproxy
group haproxy
daemon
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 1
timeout http-request 10s
timeout queue 20s
timeout connect 5s
timeout client 20s
timeout server 20s
timeout http-keep-alive 10s
timeout check 10s
frontend apiserver
bind *:6443
mode tcp
option tcplog
default_backend apiserver
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server api-server1 192.0.2.1:6443 check
server api-server2 192.0.2.2:6443 check
server api-server3 192.0.2.3:6443 check
globalセクション
デーモンとして起動し、サービスを起動するユーザーはhaproxyである。以下の通りサービス用アカウントを作成している。
# useradd --system --no-create-home --shell=/sbin/nologin node
# id haproxy
uid=109(haproxy) gid=115(haproxy) groups=115(haproxy)
defaultsセクション
デフォルトの挙動を定義している。デフォルトの動作モードは「http」としてあるが、実際に使うのはTCPモードである。
frontendセクション
全てのインターフェイス(といってもens3とloだけであるが)のポート6443で待ち受ける。
...
bind *:6443
...ここでデフォルトのhttpをtcpモードで書き換えてバックエンドに「apiserver」を指定する。このapiserverで指定したサーバーに負荷分散することになる。
...
mode tcp
...
default_backend apiserver
...
backendセクション
frontendで指定したapiserverの詳細をここで設定する。
先にserver設定を説明する。serverにはKubernetes API serverの実IPアドレス:ポート番号を指定する。frontendセクションのbind *:6443で受け取ったリクエストを、balance roundrobinとあるように、この3 IPアドレス:ポートに対し負荷分散する。
balance roundrobin
server api-server1 192.0.2.1:6443 check
server api-server2 192.0.2.2:6443 check
server api-server3 192.0.2.3:6443 check
お尻に「check」とあるのは、死活監視のことである。今述べた6443ポートの本番トラフィックの負荷分散とは別物である。何をcheckするかは、少し上の部分のこちらで定義している。
option httpchk GET /healthz
http-check expect status 200
つまりhtps://:6443/healthzにアクセスし、コード200が返れば問題ないと判断する。現にcurlしてみると、以下が返る。
# curl --insecure https://192.0.2.1:6443/healthz
ok
# curl --verbose --insecure https://192.0.2.1:6443/healthz
…
< HTTP/2 200
…
/healthzで200が返らないと、該当のサーバーは停止していると見做され、負荷分散対象から外される。
Mar 01 06:44:45 loadbalancer1 haproxy[184256]: [WARNING] 059/064445 (184256) : Server apiserver/api-server1 is DOWN, reason: Layer4 connection problem,(省略)
何秒で負荷分散対象から外されて、復旧後何秒で組み込まれるかは、defaultsセクションのtimeoutパラメーターで設定してある。
haproxy.cfgの設定ファイルが完成したら、haproxyサービスを再起動する。
# systemctl restart haproxy
# systemctl status haproxy
# journalctl -xeu haproxy
まだKubernetes API serverが未構築なので死活監視のエラーが出ているが、無視してよい。haproxyサービスがhaproxy.cfgを正常に読み込んで、サービス自体が起動していることを確認する。
ここまでの手順でKubernetes HA clusterで必要となるロードバランサ―の準備が整った。後編では主役のKubernetes clusterの構築を進める。
執筆者紹介
事業開発担当マネージャー兼
ネットワークオペレーションセンター長
間庭 一宏

IT業界で長年の就労経験を積み、国内外企業のIT課題を数多く解決してきたベテランエンジニア。鋭い眼力でテクノロジーの事業化に取り組む。INAP Japanの個性あふれるメンバーの中でも、常にポジティブな課題解決力は群を抜き、顧客からの信頼も厚い。衰えを知らぬ成長意欲で若手を引っ張るリーダーである。
- 最近の記事
-
-
- 2025年7月16日
- 「インターネットが遅い」って結局どういうことなのよ?
-
- 2024年7月12日
- コンピュータはどう動くのか、或いは、この世の大概の悪の原因 Do you know how your computer really works, or “The Root of Almost All Evil?”
-
- 2023年5月25日
- ローカルブレイクアウトしたのにSaaSは遅いまま…Unitas Networkの出番です
-
- 2022年6月30日
- エッジコンピューティング v.s. クラウドコンピューティング ~鍵を握るのはネットワークエッジ~
-
- 2021年6月17日
- 昨今のネットワークエッジとINAPのインテリジェント・ルーティング
-
